The Internet is Closing
The "open internet," a term revered by veterans in our industry for the past 20-30 years, represents an idealized digital space free from restrictions, where information flows unimpeded and access is unhindered by gatekeepers such as governments and private companies.
Yet, this open internet mirrors a battleground of ideologies, reflecting the real world's complexities and contradictions. It's a space where the lofty aspirations for freedom encounter the harsh realities of control. How does this open internet contrast with the emerging closed internet, and what are the implications of this shift?
Government-Operated Internets

The word "control" brings us to the first trend: government-operated internets, sometimes called "national intranets."
Here is a sample list of countries that do this today:
- China: Known for the Great Firewall, China has developed a comprehensive internet control and censorship system that effectively creates a national version of the internet. This system filters and blocks access to foreign websites deemed politically sensitive or harmful to public morality while promoting domestic platforms and services that comply with strict regulatory requirements.
- Russia: Russia has taken significant steps towards creating its version of the internet by developing the "sovereign internet" law. The law includes creating a national DNS system, allowing Russia to maintain control over its internet infrastructure and potentially isolate itself from the global internet in response to a crisis or foreign threat.
- North Korea: North Korea operates a national intranet called "Kwangmyong," which is entirely separate from the global internet. Accessible only within the country, Kwangmyong provides a limited set of pre-approved information and services, including a search engine, email, and state-run media. The global internet is inaccessible to the general population, except for high-level government officials and select institutions.
We've also observed governments step in to restrict internet access for political, cultural, or security reasons. These restrictions range from censoring specific websites and social media platforms to sophisticated surveillance systems.
Notable examples of this include the following:
- India: Internet restrictions in India often involve blocking access to websites and internet services, particularly in response to political unrest or to prevent communal violence. The government has periodically shut down the internet in specific regions, such as Jammu and Kashmir, citing security concerns. In one particular instance in 2019, the Muslim-majority region of Kashmir entered what would eventually be the world's longest internet shutdown—lasting 552 days.
- Turkey: Turkey blocks access to websites and content that it considers a threat to national security or offensive to national values. This has included social media platforms and news websites. The government requires internet service providers to implement these bans and has tightened internet infrastructure controls, making monitoring and restricting internet traffic easier.
When you abstract all of the above, countries and their governments have the following incentives to do this:
- Control Over Information: By filtering and censoring content, governments can prevent the spread of information that they consider politically sensitive, destabilizing, or harmful to public morals and national identity. This control extends to suppressing dissent, curbing freedom of expression, and preventing the organization of opposition through social media and other online platforms.
- Surveillance and Monitoring: Establishing a national intranet or heavily regulating the internet allows governments to monitor and surveil online activities more effectively. This surveillance capability enables them to track dissent, gather intelligence on citizens' activities, and prevent actions deemed as threats to national security or public order.
- Cybersecurity and Sovereignty: National security concerns drive some countries to isolate their digital infrastructures from the global internet to protect against cyber threats, espionage, and foreign intervention. By creating a sovereign internet, these governments aim to enhance their cybersecurity posture and protect critical infrastructure from external attacks.
- Cultural Preservation and Moral Values: Another incentive is preserving national culture and upholding moral values. By controlling internet access, governments can block content that undermines national values, promotes undesirable behaviors, and threatens cultural identity.
- Regulatory Compliance and Legal Enforcement: Implementing a national version of the Internet allows governments to enforce laws and regulations to their preference more "effectively" within the digital space. This includes intellectual property rights, data protection laws, and illegal content under national control.
While the list of countries doing this may be small, their populations are massive, and economies are growing rapidly. China and India combined are roughly 2.8B people, which makes up more than a third of the world's 8B population. For those who follow macroeconomics and politics, we're seeing a strengthening and increase of nations participating in BRICS (an intergovernmental organization comprised of Brazil, Russia, China, India, South Africa, Egypt, Ethiopia, Iran, Saudi Arabia, and the UAE).
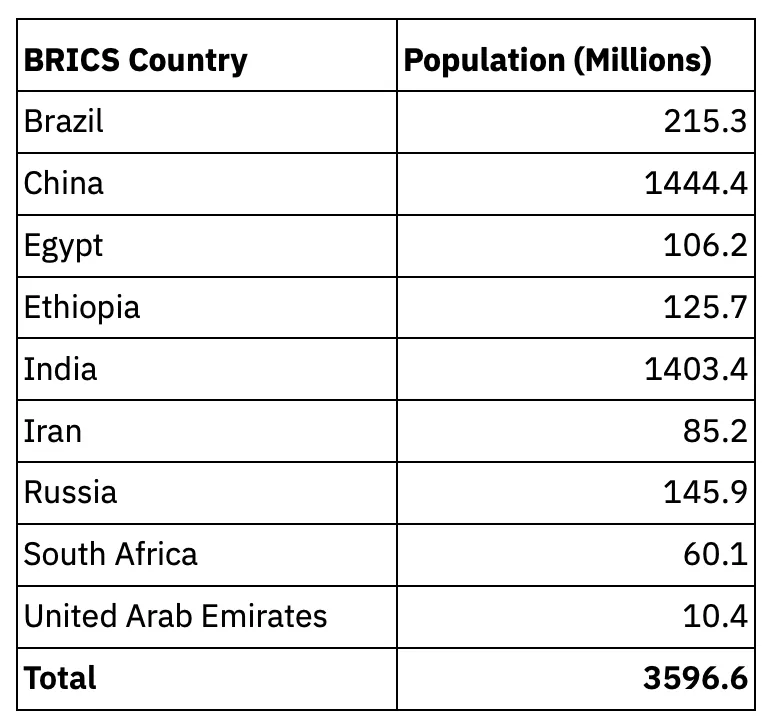
The combined population of the BRICS nations (3.596B) is roughly 10.8 times more than the population of the United States (333.9M). As these countries build tighter alliances, we may see more countries operate their internets or mesh them together as part of their cooperation. These countries could be linked together and detached from the United States, as they likely could use equivalent applications and services from other BRICS nations. It's worth noting that the idea of a BRICS internet mesh is more of a conjecture at this point in history. Nonetheless, we continue to witness greater fragmentation of the global internet we know today — sometimes called the "splinternet."
Let's couch this for now and move on to the second trend.
Artificial Intelligence & Content Scraping

Large Language Models (LLMs) represent a significant advancement in artificial intelligence. Companies such as OpenAI with GPT, Google with Bard/Gemini, Meta with LLaMa, and Microsoft with Phi are driving innovation and expanding the capabilities of these models. The enthusiasm and rapid development surrounding LLMs are not confined to these giants alone; a vibrant ecosystem of open-source projects, exemplified by platforms like Hugging Face, showcases the widespread interest and continuous evolution in this space.
Constructing a large language model involves an extensive training process that leverages diverse content:
- Web Scrapes: A significant portion of training data for LLMs comes from scraping the open web. This includes text from websites, blogs, news articles, and forums. The open web offers various topics, styles, and opinions, making it a rich source for training models to understand and generate diverse text types.
- Books and Literature: Public domain books and literature provide a wealth of well-structured text often used in training LLMs. This content can include classic literature, non-fiction books, and other long-form content that helps the model learn complex narrative structures, varied writing styles, and advanced vocabulary.
- Scientific Articles and Journals: While access to many scientific journals is restricted behind paywalls, there are also large repositories of open-access articles. These texts help models learn technical language and concepts from various fields, including science, technology, engineering, and mathematics (STEM).
- Social Media and Online Forums: Public posts from social media platforms and online forums (like Reddit) are often included in datasets to help models understand casual language, slang, colloquial expressions, and the dynamics of online communication. However, incorporating data from these sources requires careful filtering to avoid learning and propagating undesirable biases or offensive language.
- Proprietary or Closed Sources: In some cases, organizations might train models on proprietary datasets to which they have exclusive access. This could include internal documents, communications, and databases that are not publicly available. Training on such data can help develop specialized models tailored for specific industries or functions, such as legal analysis, medical diagnosis, or customer service. However, using closed content raises questions about privacy, data security, and the ethical use of proprietary data.
The New York Times, Reddit, and Stack Overflow are just 3 notable organizations that have sparked concern and litigation over their content being used to train these models. Take the NYT. Their position is that if you train an LLM on all of their headline stories, eventually, you'll be able to craft stories with a similar tone…and, most importantly, without humans.
In my conversations with some of the world's biggest content publishers, they are increasingly aware of how their content can be used by LLM operators for training purposes, often without explicit consent. In response, they've developed several strategies to protect their intellectual property and control the accessibility of their content. Here are some strategies being implemented:
- Robots.txt: Publishers can use the robots.txt file to tell web crawlers which parts of their site should not be accessed. While this relies on the goodwill of the crawler operators to respect these rules, it's a first line of defense to prevent unauthorized scraping.
- Rate Limiting and Throttling: Implementing rate limits helps publishers detect and block automated access patterns. By limiting the number of requests an IP can make in a certain timeframe, publishers can prevent extensive scraping of their content. This can be achieved with a web application firewall (WAF).
- APIs for Controlled Access: Instead of allowing open access to their content, publishers may offer a controlled way to access data. Through APIs, publishers can monitor and regulate who accesses their content and for what purpose. This is where we see companies rely on solutions like API gateways.
- Subscription Models and Paywalls: By placing content behind paywalls or requiring subscriptions for access, publishers limit the ability of scrapers to access their content freely. This approach also has the added benefit of generating revenue. Yet by doing so, these companies become more closed. Publishers must balance the need for protection with the desire to keep their content accessible and engaging for their audience.
- CAPTCHAs and Turing Tests: Requiring users to complete a CAPTCHA or some form of interactive challenge before accessing content can deter automated scraping tools, as these challenges are designed to verify that the user is human.
CAPTCHAs? Well, let's get to the last trend.
Malicious Automation & Bots

CAPTCHAs, originally heralded as the digital gatekeepers distinguishing humans from bots, have increasingly become a source of user frustration. Designed to thwart automated programs, particularly those scraping data or engaging in fraudulent activities, CAPTCHAs have become synonymous with a subpar user experience. A poignant example of their limitation was the plight of Taylor Swift fans, who lost out to bots in securing concert tickets — a scenario underscoring the need for better solutions in digital security.
CAPTCHAs, intended as digital speed bumps to impede malicious bots, often fall short. They are reactive measures, kicking in after bots initiate their activities, which highlights a significant flaw: the need for proactive, advanced security strategies.
The challenge is compounded by AI and deep learning advancements, enabling bots to solve complex CAPTCHAs, including interactive ones. This development renders CAPTCHAs increasingly ineffective, burdening human users while failing to deter sophisticated bots.
As technology evolves, the utility of traditional CAPTCHAs is waning. The arms race between CAPTCHA designers and bot developers is tipping in favor of the latter, with bots becoming faster and more adept at circumventing these security measures.
In response, the tech industry is pivoting towards a layered security approach, combining multiple detection and mitigation techniques. This includes behavioral analysis, transaction monitoring, and anomaly detection. A significant advancement in this direction is the emergence of PassKeys, offering a more sophisticated and user-friendly security alternative. PassKeys, leveraging biometric verification and cryptographic techniques, promises enhanced security without the frustrations of CAPTCHAs.
Moreover, the advent of web3 technologies brings forth innovative possibilities, such as using NFTs for authentication. This could dramatically transform online identity management and access, with blockchain technology ensuring authenticity and security.
We might witness a paradigm shift in managing online transactions and access in the near future. For instance, those passionate Taylor Swift fans who once fell victim to bot-driven ticket fraud might soon use the popular blockchain and cryptocurrency wallet to authenticate their purchases, verifying their true fandom. This shift, potentially just five years down the line, could herald a new era in secure, user-friendly online experiences, effectively rendering the traditional CAPTCHA obsolete.
Putting it All Together
As we examine the trajectory of the internet's evolution, a convergence of trends points towards an increasingly closed digital future. This closure, driven by government controls, AI content scraping, and malicious automation challenges, raises questions about the nature of our online world.
Let's contemplate some questions that emerge from the current situation:
- How will the rise of government-operated internets reshape the global internet landscape? Will each internet "segment" reflect its governing state's ideological and cultural contours? What about the diverging views of its citizens?
- What becomes of intellectual property rights in the era of AI and content scraping? How do we balance AI development with the legitimate rights of content creators?
- What new forms of digital gatekeeping will emerge as CAPTCHAs become obsolete in advancing AI? Will technologies like PassKeys or blockchain-based authentication methods like NFTs become the new standard for securing online transactions and access?
In contemplating these questions, we confront the paradox of progress. Once heralded as a boundless realm of freedom and opportunity, the internet is now at a crossroads, shaped by the technologies that promised to democratize it.
The rise of national intranets, advancements in AI, and the challenges of securing digital spaces against malicious automation are weaving a complex tapestry of control, security, and access. This new era will be marked not by the absence of innovation but by a recalibration of the principles that have long underpinned the digital world.
As we navigate this shift, our challenge will be to ensure that the internet continues to serve as a force for empowerment and connection, even as it evolves in response to the intricate demands of security, privacy, and control.